How to Actually Evaluate Your AI System?
Learn how to kickstart your journey into agency ownership with our comprehensive guide.

Alexandr Lykov
Advisor
Featured

There's a quote from measurement theory that every AI practitioner should have on their wall:
"When a measure becomes a target, it ceases to be a good measure."
It's called Goodhart's Law. And it describes exactly what goes wrong when teams optimize for benchmark scores instead of real-world performance.
Why evaluation is the hardest part of AI development
Unlike traditional software, a language model outputs free-form text. It can write prose, generate code, solve math, answer questions, hold conversations. There is no universal "correct answer" to compare against.
This makes evaluation genuinely hard — not just operationally, but philosophically.
If you don't have a rigorous evaluation framework, you end up in one of two failure modes:
— You don't know when your model gets better
— Or worse, you think it's getting better when it isn't
The 3 main approaches to LLM evaluation
1. Human Ratings
The gold standard. A human rates the quality of each model response.
The obvious problem: it's expensive and slow.
The less obvious problem: it's inconsistent.
Ask two people whether a response is "useful." One says yes — the model suggested a teddy bear as a birthday gift, that's helpful. Another says no — the model didn't specify which teddy bear to get. Both answers are defensible.
This is called inter-rater disagreement. And it fundamentally limits the reliability of human evaluation.
The fix is inter-rater agreement metrics. The most common is Cohen's Kappa — it measures how much raters agree above and beyond pure chance. If two raters randomly guess "good" or "not good," they'll agree 50% of the time just by luck. Cohen's Kappa corrects for this baseline so your agreement score actually means something.
In practice: track inter-rater agreement, hold calibration sessions when it drops, and use human ratings as a ground truth anchor — not as a scalable daily process.

2. Rule-Based Metrics

Instead of rating every output, you ask humans to write ideal reference answers once. Then you compare model outputs against those references automatically.
This unlocks fast, cheap iteration. The challenge is building metrics flexible enough to handle the fact that correct answers can be phrased many different ways.
Two widely used metrics:
METEOR — compares predicted text against a reference using precision and recall on individual words. It also penalizes wrong word order. Smarter than simple word matching — it recognizes synonyms and word stems — but still struggles with genuine stylistic variation.
ROUGE — a family of metrics. ROUGE-N counts overlapping word sequences of length N. ROUGE-L finds the longest common subsequence. Simpler than METEOR. Widely used for summarization.
The honest limitation of both: they reward models for mimicking reference wording, not for being correct. A model can be factually right and score poorly just by using different words.
For tightly constrained tasks — structured JSON, code that passes test cases, exact formatting rules — you can use exact match or regex-based evaluation. Perfectly reliable when the output space is well defined.
3. LLM-as-a-Judge
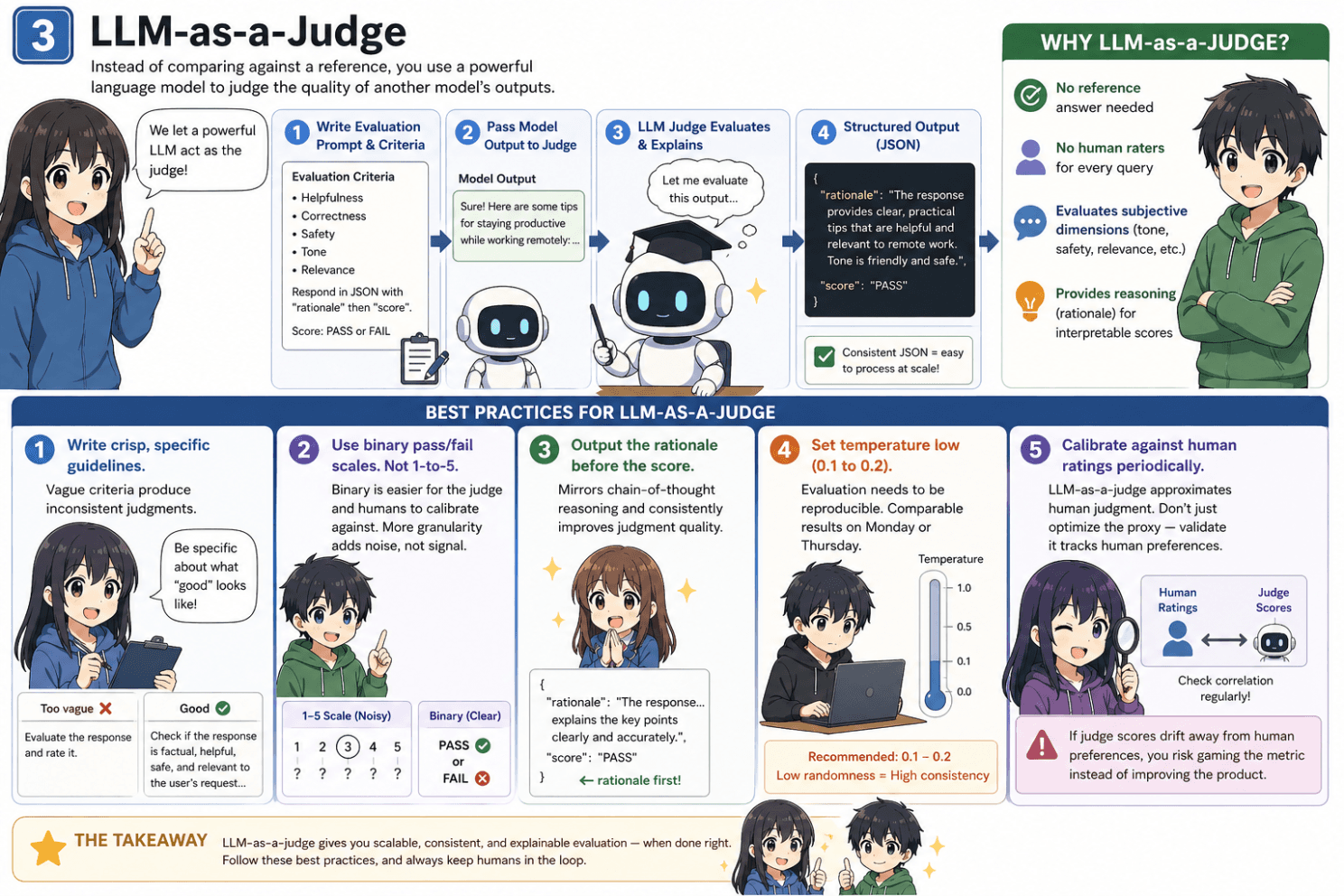
Instead of comparing against a reference, you use a powerful language model to judge the quality of another model's outputs.
The benefits are real. No reference answer needed. No human raters for every query. The judge can evaluate subjective dimensions like tone, safety, and relevance — and it can explain its reasoning, giving you interpretable scores.
The setup: write a prompt with your evaluation criteria, pass the model's output to the judge, ask for a score and a rationale. Using structured outputs (available from OpenAI, Anthropic, Google, and others), you can force the judge to return consistent JSON — easy to process at scale.
Best practices
Write crisp, specific guidelines. Vague criteria produce inconsistent judgments.
Use binary pass/fail scales. Not 1-to-5. Binary judgments are easier for the judge and easier for humans to calibrate against. More granularity adds noise, not signal.
Output the rationale before the score. This mirrors chain-of-thought reasoning and consistently improves judgment quality.
Set temperature low (0.1 to 0.2). Evaluation needs to be reproducible. You want comparable results whether you run it Monday or Thursday.
Calibrate against human ratings periodically. LLM-as-a-judge is an approximation of human judgment. If you optimize hard against judge scores and never check whether they track human preferences, you risk gaming a proxy instead of improving the actual product.
The three biases that corrupt LLM judgments
Position Bias — models tend to prefer whichever response is listed first.
Fix: run the evaluation twice with the order swapped, take the majority vote.
2. Verbosity Bias — models tend to rate longer responses higher, regardless of accuracy.
Fix: explicitly instruct the judge to evaluate substance, not length.
3. Self-Enhancement Bias — a model judging its own outputs tends to prefer its own style.
Fix: use a different model as judge — ideally one with strong reasoning capabilities.
None of these are fully eliminable. All of them are manageable with deliberate prompt design.
Evaluating factuality (this one needs special treatment)
Factuality is critically important and naturally multi-dimensional.
Consider this sentence:
"Teddy bears, first created in the 1920s, were named after President Roosevelt after he proudly wanted to shoot a captured bear on a hunting trip."
Two errors: the bears were created around 1900, not the 1920s — and Roosevelt famously refused to shoot the bear. But most of the sentence is correct. A binary good/bad judgment loses that nuance.
The current best-practice approach:
Extract individual claims from the text using an LLM. That example sentence yields roughly four discrete claims.
Verify each claim independently, against a knowledge base or using a judge model.
Aggregate into a score, weighted by the severity of each error.
You get a factuality score that reflects how wrong the text is — not just whether it's perfect.
Evaluating agents
Evaluating single-turn outputs is one problem. Evaluating multi-step agentic workflows is another entirely.
When an agent takes a sequence of actions — calling tools, retrieving information, reasoning across multiple steps — errors compound. An agent might:
— Call the wrong tool entirely
— Call the right tool with wrong arguments
— Hallucinate a function name that doesn't exist
— Use the right tool but misinterpret the result
Each failure mode has a different cause and a different fix. Wrong tool selection means adjusting a tool router. Hallucinated function names usually means rewriting tool descriptions to be clearer. Wrong arguments means improving few-shot examples.
For agentic systems, outcome-based evaluation matters most. Did the task actually complete? Benchmarks like Tau-Bench evaluate agents by checking whether the final database state matches the intended outcome — not by scoring individual steps.
The key metric for agentic reliability is Pass-hat-K: the probability that all K attempts at a task succeed. This is stricter than the more familiar Pass@K (the probability that at least one attempt succeeds). For production systems handling thousands of requests, you need consistent reliability — not occasional success.
How to read industry benchmarks
Common ones you'll encounter:
MMLU — tests knowledge across 57 academic subjects. Good for general reasoning.
MATH / AIME — tests mathematical reasoning. New test sets can be generated, so contamination is less of a concern.
HumanEval / SWE-Bench — tests code generation against real GitHub issues.
HarmBench — tests safety. Evaluates whether a model can be induced to generate harmful content. Uses a trained classifier rather than exact matching.
The right way to use benchmarks: treat them as a profile, not a verdict. A model might excel at coding and struggle at multi-step reasoning. Your use case determines which benchmarks matter.
Plot performance against cost to find your Pareto frontier — the set of models where no other option gives you better performance at the same price.
One critical warning: data contamination.
Benchmarks are only valid if the model hasn't seen the test data during training.
If a model looks suspiciously good on a benchmark, contamination is a real possibility.
For real-world signal, Chatbot Arena — where users compare model outputs side-by-side — provides a useful complement to curated benchmarks. It captures how models perform in actual use, not just on standardized test sets.
The practical takeaway
Evaluation is not an afterthought. It's the feedback loop that makes everything else in AI development work.
Start with a clear definition of what "good" means for your use case.
Build a small set of human-rated examples as your ground truth.
Use LLM-as-a-judge for scale, but calibrate it against human ratings regularly.
Track factuality, safety, and task performance as separate dimensions.
For agents, measure end-to-end outcomes — not just individual steps.
And when your benchmark score looks great but your users are complaining — remember Goodhart's Law. The metric became the target. Go back to first principles.
The teams that build the best AI products aren't the ones who move the fastest. They're the ones who know exactly what they're measuring — and why it matters.




